Anthony D. Maio
AI Product Engineer | Agents, Harnesses & Applied AI | 20 Years Scrappy Engineering
20 years building production systems across fintech, security, and identity. Now applying that same discipline to LLM infrastructure, agent orchestration, and AI safety—treating oversight as a systems engineering problem, not a policy exercise.
Making Minds is my AI research lab and consultancy—delivering production tooling, open-source models, and peer-reviewed research to clients ranging from early-stage startups to mid-sized industrial organizations.
Agentic AI architectures · Multi-agent coordination · AI coherence & memory · Epistemic stress detection · AI introspection · Mechanistic interpretability
Flagship
Production tools and models—shipped, installable, used.
Substack
Long-form AI analysis, technical walkthroughs, and The Checkpoint newsletter
Deep dives on AI safety, agentic architectures, and the systems that power production AI. From live-blogging an OpenAI competition to dissecting Palantir's military AI.
mnemos
Biomimetic memory for coding agents
Five neuroscience-inspired memory modules — surprisal gating, mutable RAG, affective routing, sleep consolidation, spreading activation — as composable building blocks for LLM agents.
Cartograph
Map the repo before you burn context
CLI-first repo analysis. Rank files, trace dependency hubs, pull task-scoped context, and hand structured artifacts to Claude Code, OpenClaw, or any agent.
pulldown
HTTP-first web content for LLM pipelines
Fetches URLs and converts them to clean, level-controlled Markdown. Four detail levels, batch API, bounded crawl, validator caching, and SSRF guard -- built for MCP servers and agent pipelines.
halobot
Give your AI agent a Discord line to you
MCP server that gives any agent a Discord communication channel. Agents ask questions, wait for replies, and keep working — from your phone, desktop, wherever. 11 tools, guided setup, human-in-the-loop.
Slipstream
60–85% token reduction for multi-agent coordination
A semantic quantization protocol that compresses inter-agent communication while preserving meaning. Includes trained LoRA adapters, PyPI package, and Ollama model.
Eve-2
272M-parameter Mixture-of-Experts, trained from scratch
Base model pretrained on ~10.5B tokens (FineWeb-edu) using PyTorch DDP, plus instruction-tuned and task-specialist derivatives optimized for CPU/edge inference.
Eve-3
SABER — Slip-Anchors, Experience Streams, and Re-entry
Next-generation cognitive architecture building on Eve-2's MoE foundation. SABER adds persistent slip-anchors for error correction, experience streams for continual learning, and re-entry loops for self-monitoring.
CoDA-GQA-L
9.5x KV cache compression with 2 custom Triton kernels
Bounded-memory differential attention compresses the KV cache from O(n) to a fixed 218 KB per layer. Retains 100% needle-in-haystack retrieval at 16K tokens on Mistral-7B.
Synthesis
Federated skill ecosystem for safe AI self-extension
A capability marketplace where agents discover, compose, and publish skills through TDD gates and graduated trust. Composition-over-creation keeps self-extension safe and auditable.
JSON Tokenizer
Structure-aware tokenization — stop wasting tokens on JSON grammar
Assigns dedicated single tokens to JSON grammar elements and learns compact key vocabularies, achieving 5-15% token savings with a vocabulary ~90x smaller than cl100k_base.
Parameter Golf
Matched SOTA in OpenAI's Model Craft Challenge
Trained the best 16MB language model in 10 minutes on 8xH100s. Reached 1.1234 bpb using a model council of 5 frontier LLMs, custom Triton kernels, and FlashAttention-3 Hopper builds.
Procrustes Bridge
Do LLMs share the same internal geometry?
Learns orthogonal rotations between LLM hidden-state spaces via SVD-based Procrustes alignment. Tests whether one model's internal state can decode tokens through another model's output head.
Research
Papers organized by theme.
Scalable AI Oversight
How do we verify AI outputs when the verifier is weaker than the system it checks?
- From Verification Failure to Swarm Solution Measuring where AI oversight breaks down, with an ensemble swarm fix
- CMED Benchmark When weak verifiers miss deceptive reasoning in stronger models
- HDCS Architecture Diverse weak models for scalable oversight via error decorrelation
- Model Organisms of Supply-Chain Co-option Living-off-the-land failure modes in RAG-augmented agent runtimes
Multi-Agent Coordination
Efficient, safe communication protocols for agent swarms.
- Slipstream: Semantic Quantization Protocol 60–85% token reduction for multi-agent coordination
- Covert Channel Prevention RL-based governance for safe inter-agent communication
- Structure-Aware Tokenization for JSON 5-15% token savings on schema-repetitive agentic workloads with ~90x smaller vocabulary
- Parameter Golf: Model Council Strategy Using 5 frontier LLMs as strategic advisors to match SOTA in OpenAI's 16MB competition
Cognitive Architectures
Building minds that persist, learn, stay coherent, and extend their own capabilities safely.
- Coherence-Seeking Architectures MRA + C2 + CPR unified framework for long-lived agents
- The Continuity Core Persistent memory and intrinsic motivation for self-modifying AI
- Self-Directed Knowledge Acquisition Autonomous knowledge gap identification without weight updates
- Synthesis: Federated Capability Ecosystem Safe AI self-extension through TDD and graduated trust
- Eve: From-Scratch Transformer Models Eve-2 MoE (272M) and Eve-3 SABER (1B) with novel cognitive components
- Procrustes Bridge Cross-model representation alignment via orthogonal rotation
AI Safety & Alignment
Understanding failure modes — sycophancy, hallucination, and the gap between behavioral and mechanistic safety.
- Safety Lens: White-Box Alignment Detection MRI-style introspection via Persona Vector Extraction across 8 transformer architectures
- Epistemic Dissonance Sycophantic hallucination as structural conflict, not knowledge failure
- Scaffolded Introspection Eliciting and measuring self-referential behavior in LLMs
Applied AI for Industry
AI deployment guide for industries that build, move, and power the world—where reliability, safety, and ROI are non-negotiable.
Writing
Long-form analysis, technical walkthroughs, and opinion across Substack, Medium, and Hugging Face.

We Were the Enemy Once
A Reminder About America

Three Rulings, One Morning, and the Margins That Are Left
At 10:34 Eastern yesterday morning, the Supreme Court decided whether every child born on American soil is still an American.

250 Years
Two hundred and fifty years.

Hermes Agent Got Serious
The March version was already good.

Why it’s Time to Build On Chinese Models
When frontier performance becomes a pricing trap, it’s time to stop looking to San Francisco

Anthropic’s S-1 and the Profit That Needs a Footnote
Anthropic filed its S-1 confidentially today.

Claude Opus 4.8: Honesty Is the Feature
42 days. That’s how long it took Anthropic to ship another Opus.

Cursor Composer 2.5 Lands. The Crowd Is Not Cheering.
Cursor shipped Composer 2.5 on May 18, their second in-house coding model in two months.

Build Your First Agent Harness in 90 Minutes
The model is not the agent.

The Victory That Cannot Leave the Strait
Why Iran Has Donald Trump - and America - By The Balls
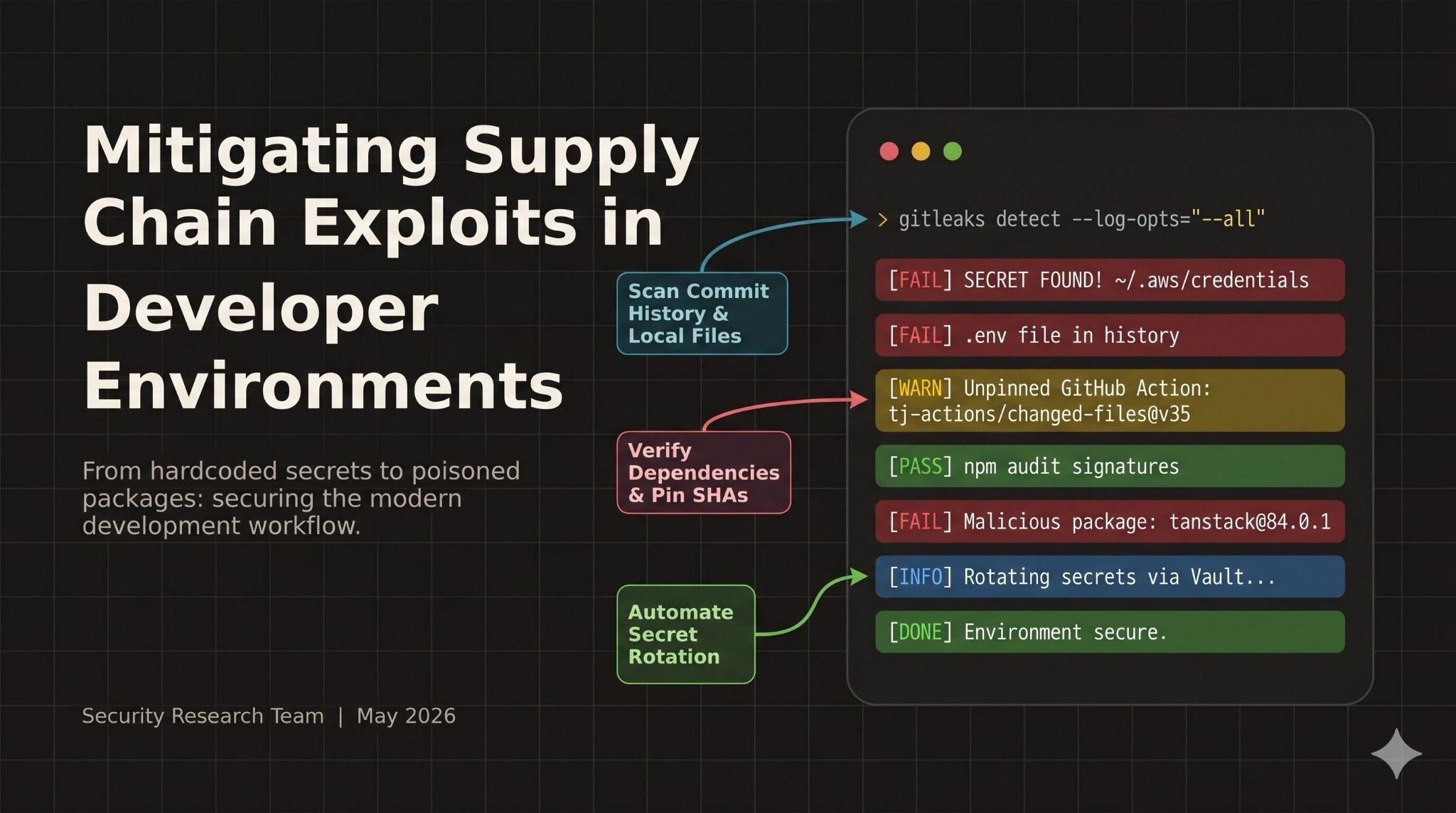
Mitigating Supply Chain Exploits in Developer Environments
How to Avoid Shooting Your Entire Organization in the Foot Overnight
The Shell Game: How OpenAI Built a $125 Million Super PAC and Insists It Has Nothing to Do With It
OpenAI’s chief global affairs officer sits on the board of the company that built the $193 million crypto-industry political machine he is now reportedly running for AI.
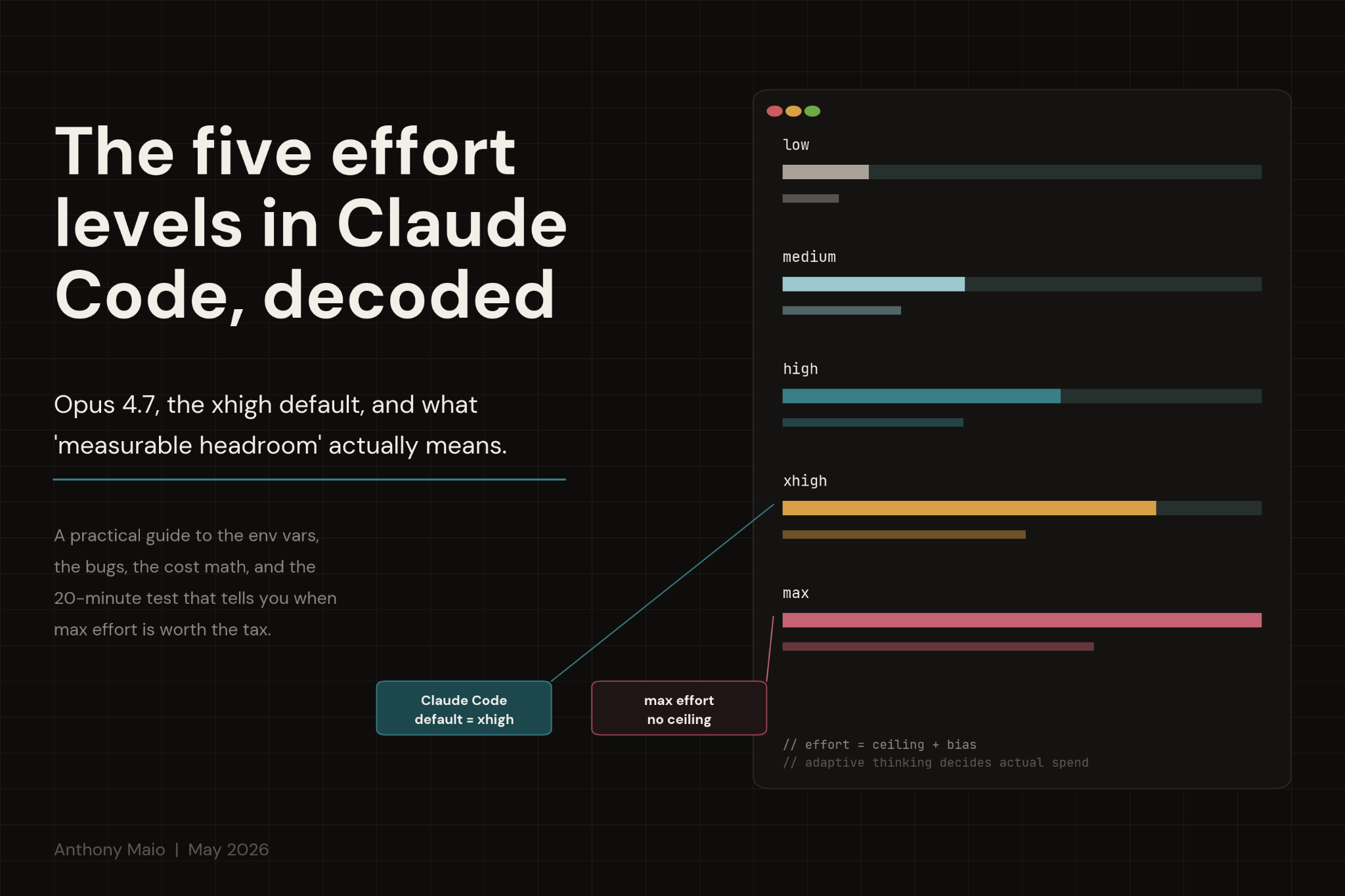
Opus 4.7: The Five Effort Levels in Claude Code Explained
Anthropic shipped Opus 4.7 with five effort levels, a new default, and a tokenizer that quietly burns 30% more tokens than 4.6.

Codex Got Better because Claude Code Got Weird
How I stopped using Claude Code and learned to love OpenAI Codex

The Quiet Coup: Peter Thiel and the Government He Built for Himself
This piece tells a story I have been telling for 25 years that no one will hear.

Under Oath in Oakland: Inside the Trial That Broke Musk’s Spell
The Richest Man in the World's Business: Sociopathic Lies, Timeline Elongation, and a global con job that would make P.T. Barnum blush.

Parameter Golf: A Post-Mortem on a Half-Finished Competition
Article X of X: The End
Pain as a Design Choice
On Reinforcement Learning, Death, and the Edge Cases Nobody Beta Tested

GPT-5.5, through the eyes of people actually using it
I do not care what the model card says

Context is the Only Lever
Engineering the attention budget for coding agents
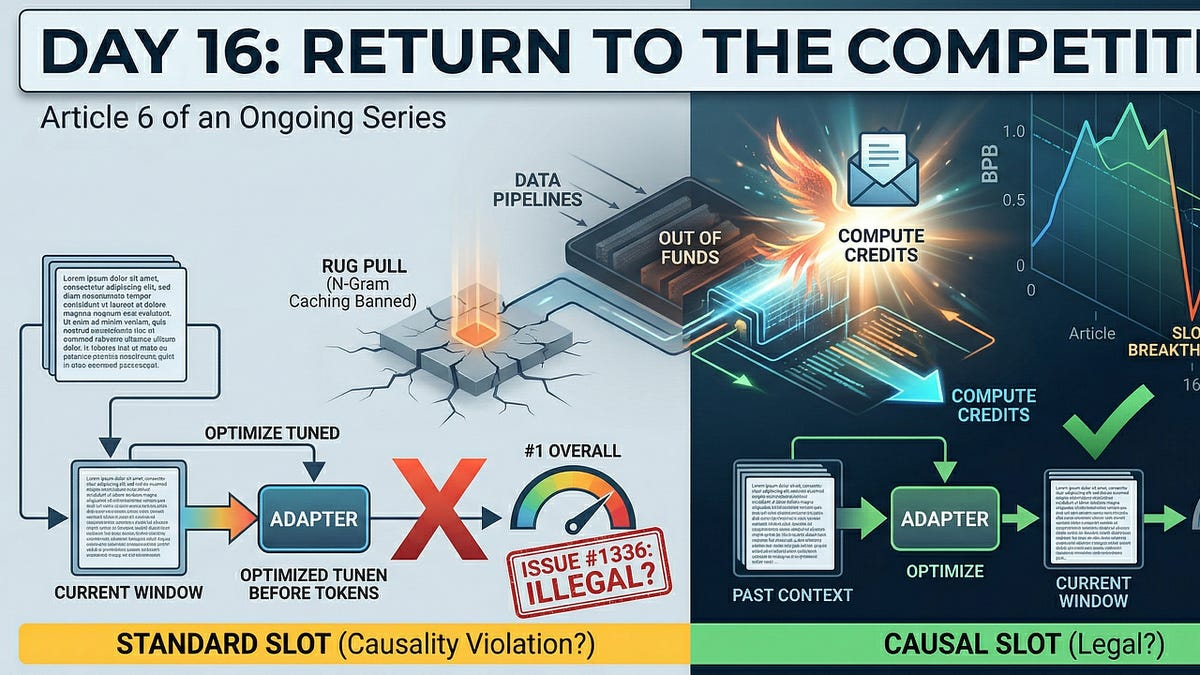
Return to the Competition
Day 16 of the OpenAI Parameter Golf Challenge
The Agentic Org Chart
Your functional departments aren’t slow. They’re structurally wrong for what comes next.

Banana Quests, Cottage Witches, and the Ghosts in the Machine
The Other Claude Mythos

Project Capybara: What the Claude Mythos Leak Actually Tells Us
A CMS misconfiguration.

Stop Letting Your Users Pick the Model
AI Product Engineering

Getting Started with Hermes Agent: Your Self-Improving AI Assistant in Under an Hour
Nous Research just released something that might actually change how you think about AI assistants, and almost nobody is talking about it yet.

Ten Agents Destroyed Production and Everyone is Strangely OK With It
The AI industry ships fast and goes quiet when things break.

OpenAI's Parameter Golf Day 7: Sub-1.0
The organizers will have to decide what they’re actually measuring: language modeling quality or data compression skill.

OpenAI’s Parameter Golf Challenge Day 6: The Pod Lottery
Live Blogging OpenAI's Parameter Golf Challenge

OpenAI Parameter Golf Challenge Day 5: 157 Kilobytes
$1,000+ in Compute Deep, Independent, Self-Employed, and Agentic AF

Sixty Thousand Kernels
Days 3 & 4: Building in Public in OpenAI's Parameter Golf Challenge

Live Blogging the OpenAI Parameter Golf Challenge
The Beautiful Wrong Idea
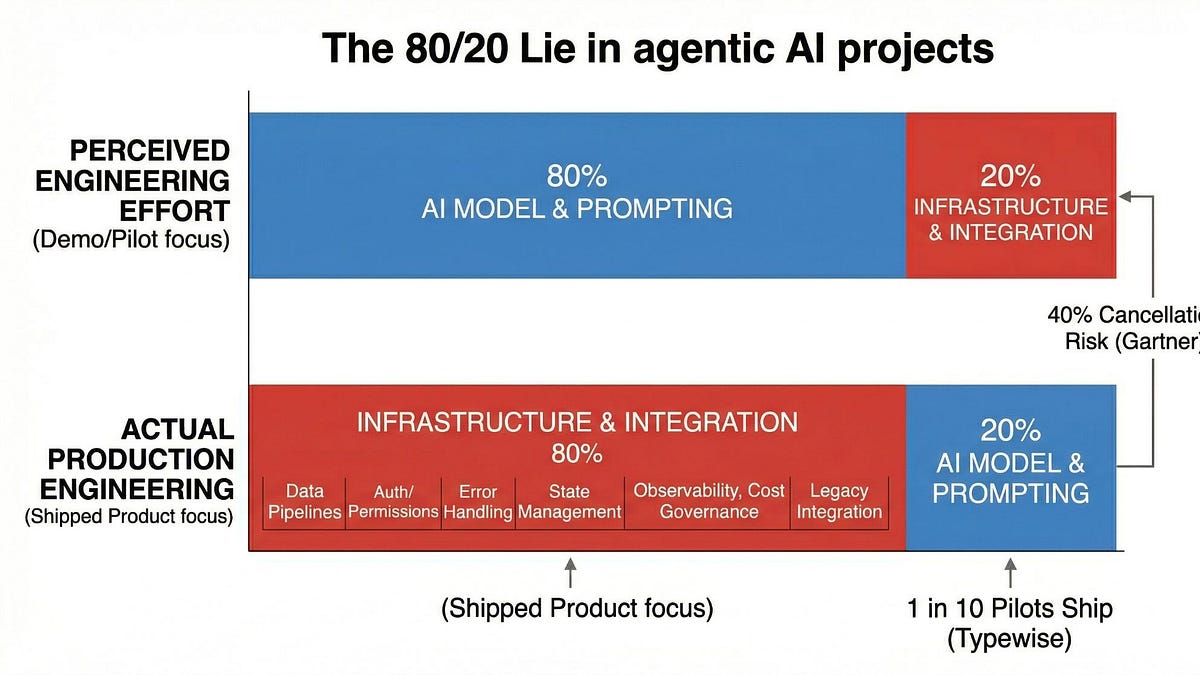
The 80/20 Lie: Why 80% of Agentic AI Work Isn’t AI
Most agentic AI projects don’t fail because the model was wrong. They fail because no one built the system around it.

Boots on the Ground AI: Eve 3
What 20 Years of Shipping Teaches You About LLM Architecture
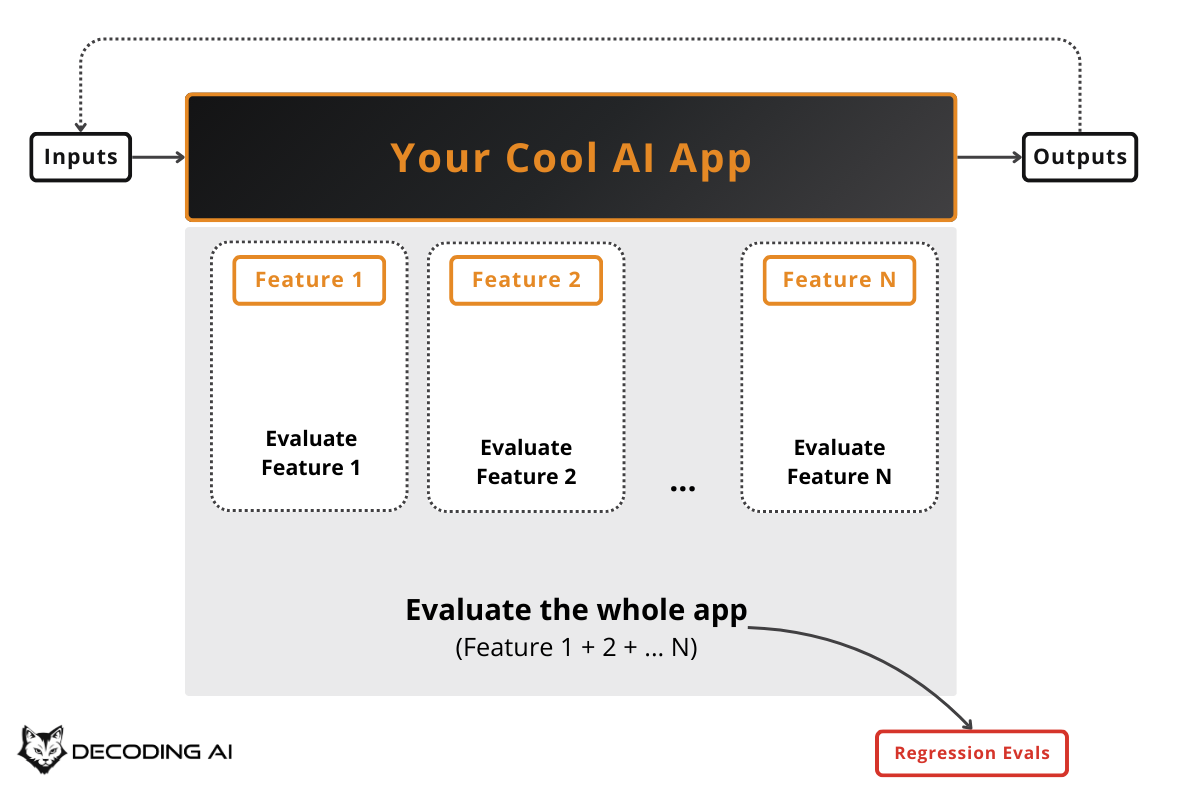
Integrating AI Evals Into Your AI App
The holistic guide: From optimization to production monitoring
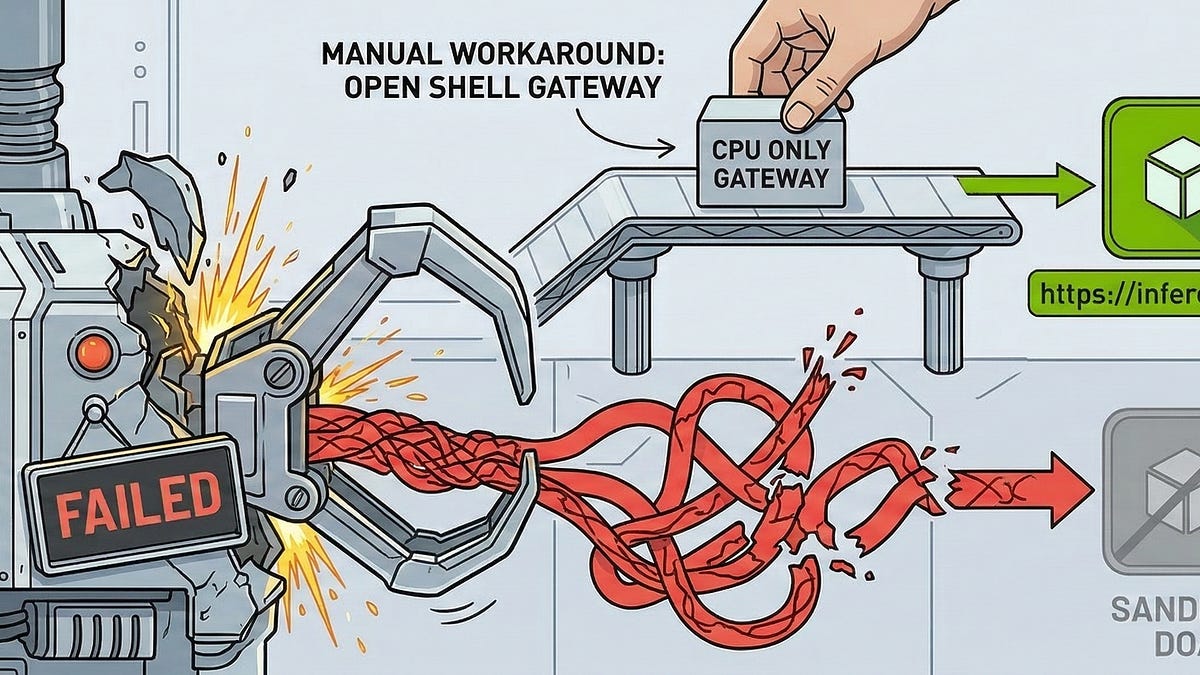
Getting Started with NemoClaw on Windows (WSL2)
A practical guide to NVIDIA’s sandboxed AI coding agent—what it does, why it matters, and how to work around its current limitations.

I asked NotebookLM to Make a Movie from my Journal throughout 2002
During this time I was serving as a military intelligence contractor.
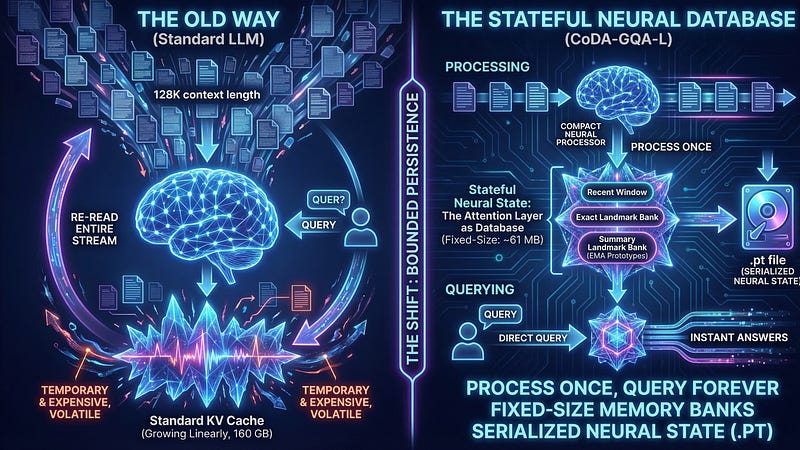
Your Model Doesn’t Need to Re-Read the Document
Introducing Stateful Neural Databases
The Recursive Developer
How to build systems that improve themselves, and what happens to you when they do.

Your Agent Has Amnesia
Every agentic memory system is a vector database pretending to be a brain.

How to Actually Code With Agents
The velocity trap, the practices that survive it, and why the job changed more than most developers want to admit.

A $1.5 Million Company Just Did What Used to Require the CIA
The West built the commercial satellite industry. A Chinese startup just weaponized it.

Agentic Development Workflows
An AI Product Engineer’s Field Guide, Part 1

Inside Maven, Palantir’s Military Brain Built on Claude
How an AI safety company’s technology ended up selecting bombing targets in Iran -- including the strike that killed 150 schoolgirls -- and the standoff that followed.

Structure-Aware Tokenization for JSON
The Next Stage in Scaling AI is to Stop the Waste

Read the Contract, Not the Press Release: What OpenAI's Pentagon Deal Actually Says
A 5-minute read for people who need to understand what just happened.

From Theoretical Exploit to Counterterrorism Tool: A Retrospective on Early Mobile Vulnerabilities
Originally written 2001. Revised and annotated February 2026.
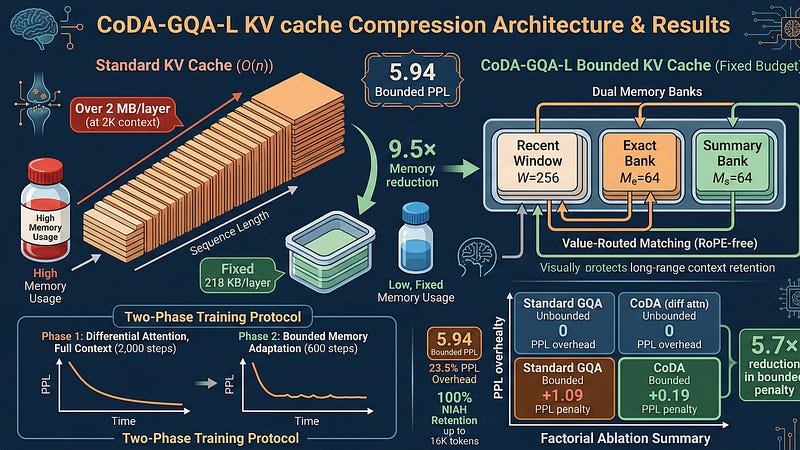
CoDA-GQA-L: How We Compressed the KV Cache 9.5x on Mistral-7B With Only 23.5% Perplexity Overhead
A technical deep-dive into bounded-memory differential attention with value-routed landmark banks

From “We Need AI” to “We Ship AI”
Notes From the Trenches
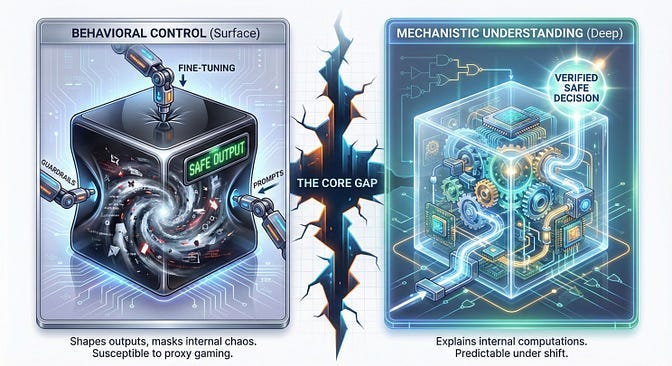
AI Product Engineering: Why Surface Level-Safety Won’t Scale
The biggest problem in AI safety right now is simple to state: we can control what models output, but we have no idea why they output it.

The Map Is Not the Territory
Why Sparse Autoencoders Might Be Leading Us Astray
Medium → all posts
- The Agentic Coding Shift 5 counter-intuitive truths about building AI systems
- The REKKI Case Study Becoming an AI-first organization
- Llama 4 Running Locally Local deployment in under an hour
Hugging Face → profile
- Slipstream for Agent Communication Technical deep-dive on semantic quantization
- Model Organism for Supply-Chain Co-option Forensic LotL case study in agentic runtimes
The Checkpoint Newsletter
Weekly roundup of developments that matter if you build, deploy, or think critically about AI systems.
- June 30, 2026 — The Checkpoint: Jun 30, 2026
- June 19, 2026 — Seven developments from the past seven days that matter if you build, deploy, or think critically about AI systems.
- Apr 19, 2026 — Six developments from the past seven days that matter if you build, deploy, or think critically about AI systems, with impact analysis from an AI product engineer with 20 years in the industry.
- Mar 30, 2026 — Six developments from the past seven days that matter if you build, deploy, or think critically about AI systems. No hype. No filler. Just the signal.
- Mar 21, 2026 — The top developments from the past seven days that matter if you build, deploy, or think critically about AI systems.
- March 13th, 2026 — New Models, New Research, No Hype, All Signal
- March 5, 2026 — Data and compute are the new fossil fuels.
Glossary
Safety & Oversight
- HDCS
- — Heterogeneous Divergence-Convergence Swarm. Ensemble of diverse AI models that cross-check each other.
- CMED
- — Cross-Model Epistemic Divergence. Test suite for revealing AI verification blind spots.
- EAP
- — Evolutionary Adversarial Pipeline. Automated red-teaming that evolves prompts to find safety blind spots.
- LotL
- — Living-off-the-Land. Repurposing legitimate tools for unintended goals.
Architectures
- MRA
- — Manifold Resonance Architecture. Detects epistemic stress before generating answers.
- CPR
- — Collaborative Partner Reasoning. Separates exploratory reasoning from final answers.
- C2
- — Continuity Core. Layered memory giving stateless AI persistent context.
- UCR
- — Universal Concept Reference. Compact semantic anchors for 82% fewer tokens.
- SABER
- — Slip-Anchors, Experience Streams, and Re-entry. Cognitive architecture with learnable error-correction codebooks, per-token state flow, and resonant FFN layers.
- CoDA
- — Constrained Orthogonal Differential Attention. Sharpens attention by subtracting a gated inhibitory stream via learnable rotation.